This post is brought to you by Christopher Wilson, Knowledge Lead at the engine room. Christopher manages the design and implementaion of research projects at the engine room, and supports partners in the use of data to realize programming objectives. Christopher is partnering with Jun Matsushita, information innovation lab (iilab) to facilitate the Wednesday session on Interoperability Standards for Public Good Data.
We are awash in a sea of data. Produced by all kinds of actors for a variety of reasons, and there’s more on the way all the time. On the plus side, much of this is being produced or aggregated for the public good, and implies tremendous potential for transparency, accountability, education, knowledge and efficiency across a broad range of sectors. A quick scan of the #OKCon program shows just how broad. On the minus side, it can be overwhelming. And this raises the big question about what open data is actually being used, by whom and for what?
One might argue that as a community, we aren’t asking this question enough. It’s revealing to see how much of the open community’s attention is still focused on the supply side of open data. Open, access, release, connect: these are some of the most common words in the program—supply verbs every one.
This can be justified to some extent by the state of play in open. The norm of #open is still being established, and there remains a tremendous amount of data that is not yet produced, collected or released. But we also know that there are demand-side challenges, and that uptake is not matching release as much as we would like. For the lofty aim of informing and enabling citizens, data literacy poses a real problem with no obvious, cookie cutter solution. And ironically, it’s a problem that’s exacerbated by the increasing production and release of data on public interest issues.
Access to complementary data sets covering the same phenomenon would at first glance seem to be a boon for advocates or researchers seeking to better understand complex social phenomena or power dynamics. Working on corruption in the extractives industry? What better than to have hard data both from the government, the companies, the media, citizen reporting mechanisms and international regulators? Hard evidence on what’s really happening? Great!
 But here enters another well-known thorn in the side of open data: the lack of standards. This issue gets raised a lot in the abstract, and there are differing opinions on whether it is a fundamental or a constructed problem. Would interoperable social good data actually help advocates and researchers working on social change issues, or will differences in data from different producers frustrate any attempt to make sense of it anyway? Are data standards even feasible, even for specific industries or data types, or is it way too early in the game to even be suggesting this since most of the data being opened is just so bad? We don’t think anyone has the answers to these questions in the abstract, but are pretty convinced that they are questions we need to start asking in specific use cases.
But here enters another well-known thorn in the side of open data: the lack of standards. This issue gets raised a lot in the abstract, and there are differing opinions on whether it is a fundamental or a constructed problem. Would interoperable social good data actually help advocates and researchers working on social change issues, or will differences in data from different producers frustrate any attempt to make sense of it anyway? Are data standards even feasible, even for specific industries or data types, or is it way too early in the game to even be suggesting this since most of the data being opened is just so bad? We don’t think anyone has the answers to these questions in the abstract, but are pretty convinced that they are questions we need to start asking in specific use cases.
We’ll be holding a workshop on Monday to do exactly that. The Standards and Interoperability workshop will come with 4 specific use cases (international aid in Nepal, extractive industries in Nigeria, Internet freedom in Iran and tech and accountability initiatives globally), each with a set of different, complimentary (and often contradictory) data sets—we call them data clusters. We’ll spend the beginning of the session talking about some of the interoperability issues and background for each of the use cases. Then we will dig in and start hacking out the different data clusters in small groups, trying to understand what the data tells us, what we can do with it, and what the obstacles are. We’ll be looking for insights, advocacy tools or just plain strategies. Frankly, we don’t really know what these data clusters have to offer. But we have lots of specific questions.
At the end of the session, we hope that this exercise will give us some indication about whether meshing data can actually provide useful tools, where the obstacles for doing so lie, and if there are any tricks for automating interoperability that could be further tested (at least for these use cases). We might not answer these questions definitively, and they are by no means the only questions, but we hope to get a little bit smarter about what this whole question of standards actually means, and by extension, what it means for thinking about the demand side of open data.
We only have room for 10 spots in the workshop, which means we will likely have to focus on just two use cases. If you would like to join us, sign up at [email protected]!






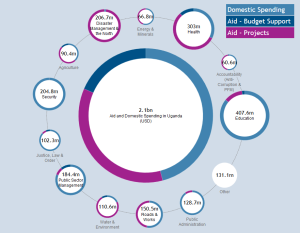 Aid, climate finance, extractives, government budgets, humanitarian aid, contracts and organisation identifiers: there are now a large range of initiatives to open up data on developmental resource flows.
Aid, climate finance, extractives, government budgets, humanitarian aid, contracts and organisation identifiers: there are now a large range of initiatives to open up data on developmental resource flows.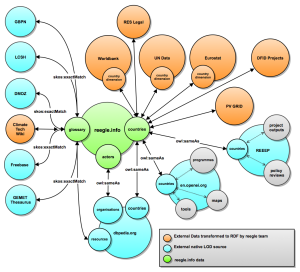 Often these snippets of information are retrieved across different research fields and later stored in hundreds of different information silos that are not connected to each other. The same can be said about modern energy systems that combine new and conventional sources of energy, centralized and on-site generation and a complex distribution infrastructure. Again, a lot of data is needed to smooth the way for the transition towards clean energy.
Often these snippets of information are retrieved across different research fields and later stored in hundreds of different information silos that are not connected to each other. The same can be said about modern energy systems that combine new and conventional sources of energy, centralized and on-site generation and a complex distribution infrastructure. Again, a lot of data is needed to smooth the way for the transition towards clean energy.
